DeepIQ Data Integrator is DeepIQ’s managed data movement and pipeline operations layer. It standardizes how industrial time-series data is requested, validated, delivered to cloud targets, and monitored in production.
DeepIQ Data Integrator now supports AspenTech IP.21®, providing a managed end-to-end experience from IP.21 to optimized cloud data platforms. Teams can configure, validate, deploy, and monitor IP.21 pipelines from a single interface.
This capability addresses a common pain point in industrial data programs; moving IP.21 data to the cloud typically requires a stitched set of tools and handoffs across OT and IT.
The Current Challenge
Moving IP.21 data to the cloud often becomes a stitched pipeline across OT and IT, including:
IP.21 extraction in the OT network zone
An OT landing zone, plus tools to monitor and move data across boundaries
Cloud ingestion pipelines and transformations into analytics-ready time-series tables
Multiple monitoring systems, fragmented alerting, and custom exception handling
Ongoing coordination between OT and IT teams to deploy changes and resolve failures
This patchwork slows onboarding, increases operational burden, and delays analytics outcomes.
End-to-End Setup in Under One Minute
DeepIQ Data Integrator simplifies pipeline creation into a consistent workflow:
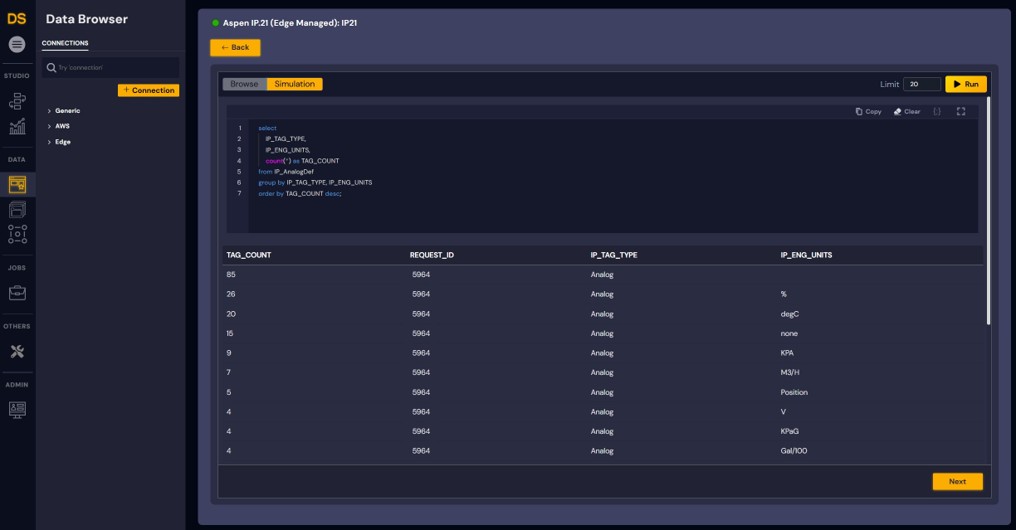
1. Create and Validate data requests
Figure 1: Data Integrator for IP21 in Simulation mode to validate requests and results
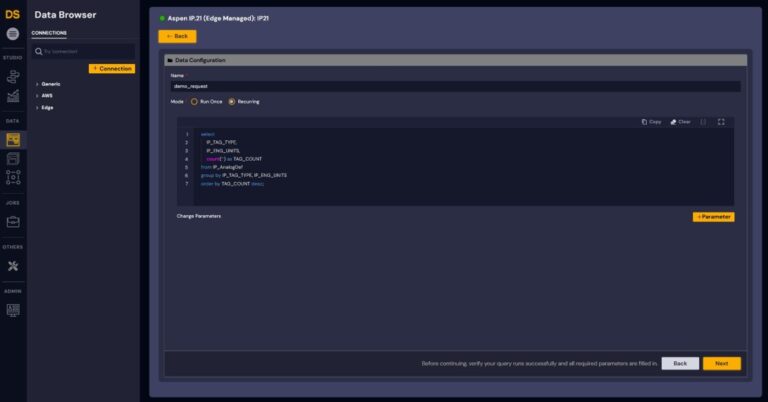
2. Choose a workflow type (streaming or batch)
Figure 2: Request Type configuration
Run Once and Recurring modes (In Figure 2) enable users to schedule their edge data pipelines where needed with the flexibility of parameterizing their requests.
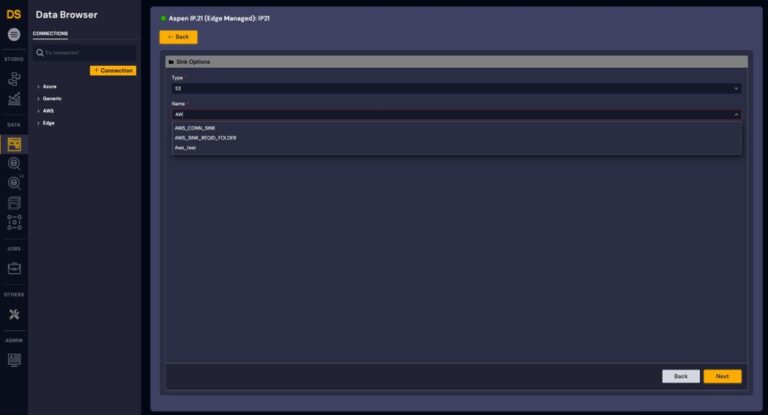
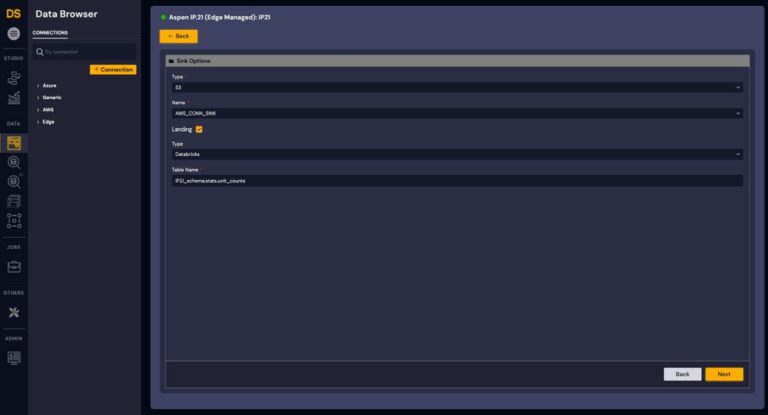
3. Select a sink and configure target database and table
Figure 3: Sink Options - Staging Area selection
Figure 4: Sink Options - Landing Area selection
4. Deploy an end-to-end pipeline
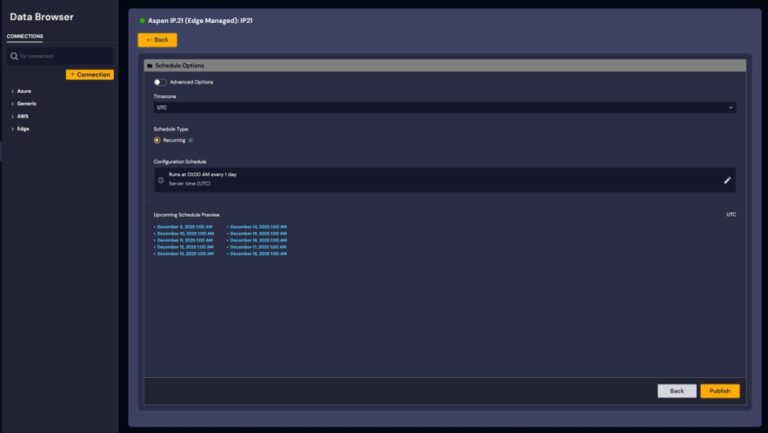
Figure 5: Scheduling Options for batch requests
Choose the Workflow That Matches Your Use Case
Streaming Workflows (Low Latency)
Use streaming workflows when you need near real-time data for operations, alerting, and fast analytics.
Supported streaming sinks:
Amazon Kinesis
Azure Event Hubs
Typical outcomes:
Faster time-to-data for operational monitoring and real-time use cases
Continuous delivery of IP.21 time-series data into downstream systems
Batch Workflows (Cost Efficient, High Throughput)
Use batch workflows when you want scheduled loads, backfills, and efficient movement of larger data volumes.
Supported batch sinks:
Amazon S3
Azure ADLS Gen2
Delta Lake
Snowflake
BigQuery
Redshift
Typical outcomes:
Reliable scheduled ingestion for reporting and analytics
Easier historical loads and reprocessing when requirements change
Production Operations in One Place
DeepIQ Data Integrator provides a single operational surface for production pipelines:
Monitor all IP.21 pipelines from one screen
Receive alerts when failures occur
Reduce manual exception handling and runbook sprawl
Troubleshoot faster with end-to-end visibility
Why It Matters (Business Outcomes)
Faster onboarding
Move from project-based, multi-tool pipeline setup to a repeatable configuration workflow
Lower operational burden
Reduce failure points by eliminating tool sprawl
Centralize monitoring and alerting for production pipelines
Less OT and IT coordination overhead
Reduce ticket ping-pong and handoffs with a single operational pane
Simplify troubleshooting by making the end-to-end flow visible in one place
More analytics output
Onboard more assets, tags, and sites because setup is fast
Deliver consistent time-series structures that reduce wrangling and accelerate insights
Summary
DeepIQ Data Integrator’s new IP.21 support replaces stitched pipelines with a single-pane, end-to-end workflow that supports both streaming and batch patterns. Teams can deploy pipelines in under one minute, monitor them in one place, and deliver IP.21 time-series data to modern cloud destinations with less operational overhead.