
databases as your cloud persistence layer. Snowflake has several inbuilt capabilities that are a
prerequisite to a good time series database. It offers infinite scalability, cost-effective storage, and
fast query response times both for point reads and analytical queries. Using the same database both
for operational and EDW workflows will vastly simplify cross-functional analytics that require
integrated data sets. Can Snowflake fulfill your time-series data needs too?
In this whitepaper, we deep dive into this topic and argue that the answer to the above question is a
strong yes if you leverage DeepIQ as the data engineering layer.
Background
Snowflake has several important features that make it a good candidate for time-series data.
- Snowflake is a hybrid columnar type of database and the values of a tag in a time-series table can be sequentially stored one after the other rather than row by row. This is a good design pattern for time series data because it matches the standard consumption pattern and minimizes the “extra” data that Snowflake must load to provide the results of a query.
- Snowflake micro-partitions data automatically according to its ingestion order by default. As time series data is typically ingested in time sequence, Snowflake will partition the data accordingly. This again matches typical consumption patterns for time-series data (reading the values of a tag or tag over a given time) and allows Snowflake to efficiently “prune” that underlying storage files storing the time series data. Consequently, a table containing a decade’s worth of time series data can be queried just as quickly as one containing just a week’s worth.
- The separation of storage from compute, and the “immutable” data design choices that are a part of Snowflake make things such as simultaneous ingestion of high-rate time series data and analysis of that data a non-issue. Users can stand up a small compute instance to support continuous data ingestion of thousands of rows per second and at the same time against that same growing data set leverage a large multi-processor set of compute instances to process that data for machine learning use cases, etc.
Despite these architectural advantages, there are important issues that need to be addressed for Snowflake to replace your existing time-series persistence layer. These issues are described below:
1. Ingestion
Firstly, due to strict network security restrictions on control networks, operational data sources, including SCADA, Historian, or Control systems, may not be directly accessible from your cloud tenant. Even if the operation network is accessible, standard data extraction software does not support the protocols or framework required for connectivity to the sources.
2. Real-Time Analytics
Secondly, the volume and velocity of time series data are an order of magnitude higher than the standard IT sources. Many times, these raw data sources may have to be enhanced with provenance, data cleansing, or machine learning model results before persistence. To support these use cases, you will need data ingestion software that scales to high data volumes and velocities and can enrich data during the ingestion process.
3. Data Engineering
Additionally, time series data has unique transformation requirements. For example, you will have to impute to remove missing data, interpolate data to the required frequency and remove high-frequency noise. To perform these analytics at scale, you will need to develop complex user-defined functions.
DeepIQ provides a straightforward answer to all these challenges. In this whitepaper, we use a sample use case to illustrate how DeepIQ and Snowflake provide an ideal solution for a real-world use case.
DeepIQ Introduction
DeepIQ is a self-service {Data + AI} Ops app built for the industrial world. DeepIQ simplifies industrial analytics by automating the following three tasks:
- Ingesting operational and geospatial data at scale into your cloud platform.
- Implementing sophisticated time series and geospatial data engineering workflows; and
- Building state of the art ML models using these datasets.
This whitepaper will explain how you can build a production-grade data pipeline with real-time streaming data from your industrial systems into your Snowflake in minutes. Using a real-world use case, we will explain how to build these data pipelines and conclude with a brief discussion about the data apps you can build with this technology.
Use Case
In this use case example, the data source is an on-premise OPC server that is connected to a control system. Our objective is to move this streaming data into Snowflake. However, the raw data frequency is irregular, making it difficult to process. Our first goal is to persist this raw data in a Snowflake data warehouse.
Our ultimate objective is to generate a table with regularly spaced 1-hertz data that can be easily consumed by downstream analytic processes. With a consistent frequency, the data can be easily visualized and used to derive meaningful conclusions.
Architecture
For this use case, we will use the architecture shown in Figure 1. We have a DeepIQ edge connector that uses an OPC UA client to connect to the on-premises streaming data source. DeepIQ edge uses an encrypted and compressed data channel to push messages to the AWS cloud and land data into the storage layer of your choice. In this use case, we will persist incoming high-volume time series data into an AWS Kinesis stream and use DeepIQ’s DataStudio software to format the data and persist it into Snowflake. We then use another DataStudio workflow to read the raw data from Snowflake and create a cleaned time series table with 1-HTZ frequency data. DeepIQ’s DataStudio workflow leverages Apache Spark’s distributed and parallel computing framework to scale to high volumes.
Note: We can leverage other services like Azure EventHub, Google PubSub, or Kafka instead of AWS Kinesis.
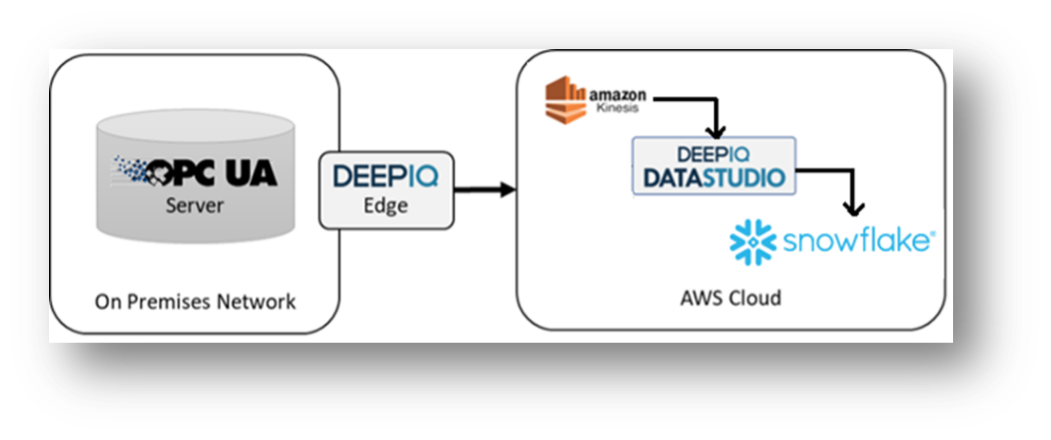
DeepIQ’s edge connector allows users to parallelize data read requests and maximize throughput to the extent supported by the source system. In this whitepaper, we will focus on the throughput of the cloud with different strategies.
Approach and Results
We use DeepIQ’s DataStudio in the AWS environment for this sample use case. We will also use an installed DeepIQ Edge connector on our on-premises network where the time series data source is available. DeepIQ edge installation is also GUI based and hassle-free.
Once deployed, we are ready to build the production pipeline from the historian to the AWS cloud. This task is a three-step process.
- We configure DeepIQ Edge to publish data to an AWS Kinesis Data Stream/Topic.
- We use a DeepIQ DataStudio workflow to read data from Kinesis and write it to Snowflake.
- We use another DeepIQ DataStudio workflow using proprietary components to read and process data. These include time series data transformation and cleansing techniques such as interpolation.
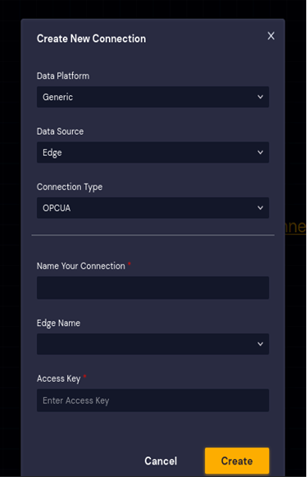
We will first create a request for data using DataStudio’s edge control panel. We specify the tags of interest in our data request, as shown in Figure 2.
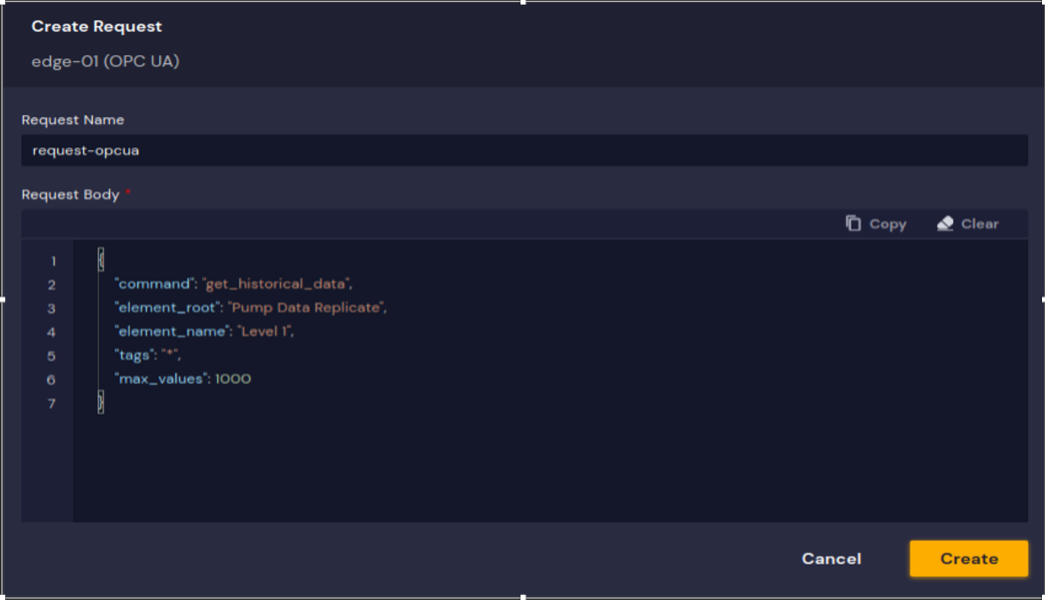
Once the data request is submitted, the DeepIQ Edge software processes the request by submitting it to the OPC UA server, as shown in Figure 3. The OPC UA server will publish the data into the configured Kinesis topic.
You can monitor the process and find all the available tags in DataStudio, as shown in Figure 4.

DeepIQ’s DataStudio supports data ingestion into Snowflake in both Spark Batch and Streaming modes.
Figure 5 is a sample workflow showing the Snowflake data ingestion in the streaming mode. We are reading data from AWS Kinesis, transforming the data to the required schema, and persisting data into a Snowflake Table.
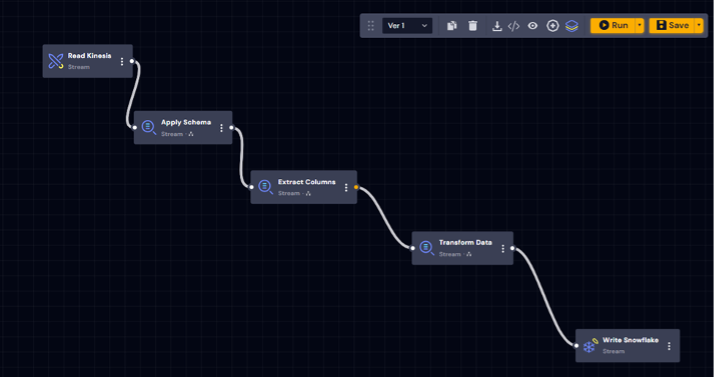
Now, let us review the performance and scalability aspects of DeepIQ DataStudio components.
Figure 6 is a DataStudio workflow that writes to a Snowflake table in high-performance batch mode. We limited the Spark cluster size to twenty cores and 70 GB to test our workflow performance. Using this workflow, we were able to ingest the 10,000 records in under one second. DataStudio uses the underlying spark cluster to submit records to Snowflake by parallelizing the load to each executor, which helped us scale out and achieve the throughput of 10,000 tags per second. We can scale the ingestion process further by increasing the partitions and executors (cluster size) for larger datasets.
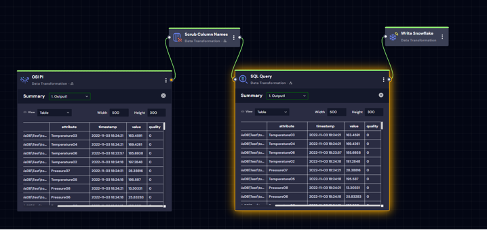
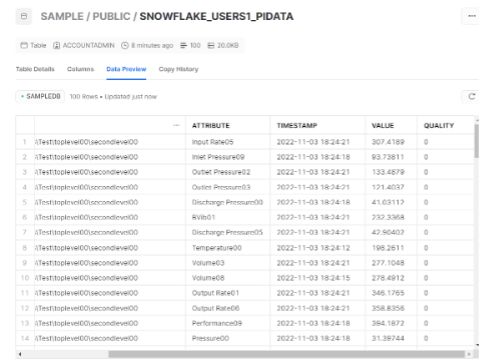
In this use case, the data is captured with a timestamp as the index for different tags/attributes with their value and quality. We can also expand to capture additional attributes like asset names, location, etc
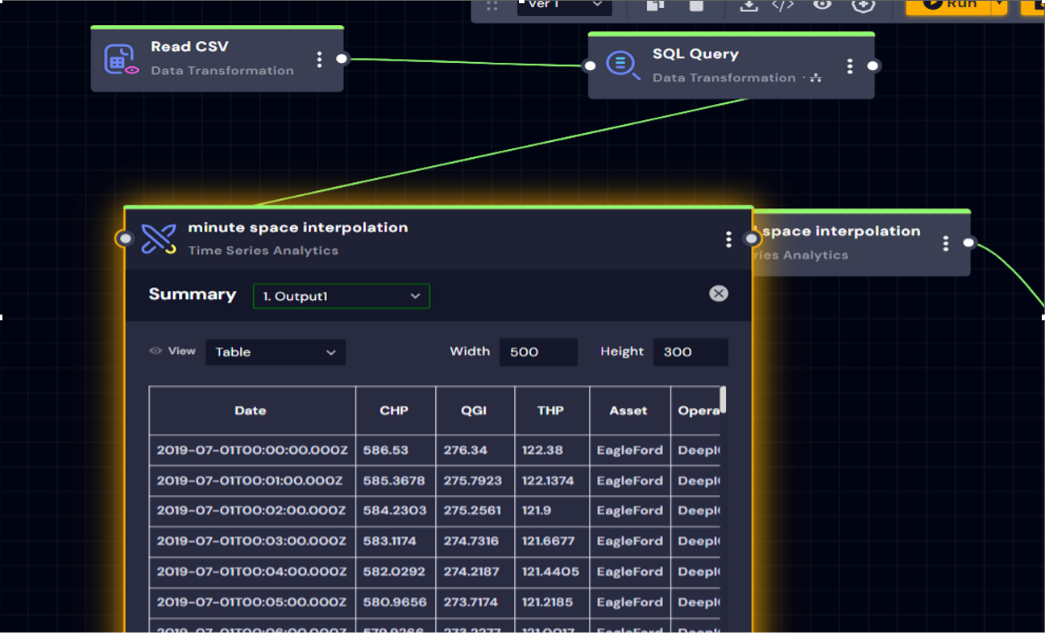
Now, let us look at the time series data processing needs. DeepIQ’s DataStudio offers components for smoothing, approximation, and interpolating time series data with various algorithms. Figure 8 shows a workflow that reads data from the raw storage table and creates a regular-spaced data table after removing outliers. In this workflow, we use cubic interpolation to interpolate data and an STD outlier removal algorithm to remove outliers.
Other Use Cases
Now that you have a data pipeline that consistently moves clean time series data into your Snowflake data warehouse, you have the foundation to build powerful data applications. In our previous whitepaper, which is available at DeepIQ | Predictive Maintenance, we discussed how to implement predictive health models even with sparse failure data.
In addition to streaming data into Snowflake, DeepIQ offers the capability to connect directly to AWS Kinesis using Spark Structured Streaming. This enables you to execute machine learning models and calculate KPIs in real-time, providing you with the ability to make informed decisions quickly.
Conclusion
In this whitepaper, we explained how DeepIQ simplifies the process of persisting and analyzing time series data in Snowflake. As illustrated in the use case, Snowflake is a powerful cloud service platform that could be used as a time series database and as a single platform for both IT and OT data. With DeepIQ’s DataStudio, you can realize the full potential of your Snowflake Data Warehouse by ingesting both your operational and IT data at scale and developing innovative solutions that maximize the value of this data. For more information, please get in touch with info@deepiq.com.